如何封装一个可获取URL参数的函数?正则表达还是很强大的,平时工作中正则用的比较多

首先开头的http代表了所使用的获取资源的协议,该URL显示获取这个网页资源要使用的是HTTP。然后,ifo.cer.ch这部分指明了资源所在的服务器,它是一个域名(domaiame)。域名将难以理解的网络地址抽象为一个个可以被人类记忆并理解的英文单词组合,便于人们的使用和访问。之后的/hy
url怎么获取
任务是根据获取2个国外垂直产品商城网站指定分类的的产品详情页描述和一个辅助信息。 每个产品对应一个独有的货号(品牌方发行的统一的货号)。 获取2个目标网站的货号+标题+描述+一个其他的辅助信息(全部信息都位于详情页。)以下是一个示例程序(Pytho 3语言),可以帮助您获取目标网站的产品信息:
心灵紫云英:什么是网页爬虫 爬虫是一种通过技术手段迅速高效的从互联网上公开的页面上自动在指定规则下获取各种数据的技术。一个简单的爬虫即通过一-个或多个URL访问,获取到指定页面元素内容保存到本地文件即可。复杂的爬虫程序会将访问多个URL下面的超链接URL全部爬取到,将每个URL页面的数据保存至数据库,反复递归此过程,直到将满足预定条件全部页面爬取完,将数据缓存生成索引以供下一-步使用,它被大量应用到搜索引擎_上进一步为人们提供各类搜索服务比如,百度搜索引擎、谷歌搜索引擎等,它也被大量的应用到企业内部上,为企业节省获取数据的成本,提升工作效率。1、由于爬虫异于常人访问,会造成短时间内服务器吞吐量过大,CPU升高,负载过重,影响正常用户的访问,或出于对数据保护网站所有者会设置验证码、滑动窗口等需要人为交互的操作来保证访问确保不是爬虫程序,因此爬虫需要考虑到规划、负载,还需要讲“礼貌”2、通常网站所有者会在网站根路径下放置- -个robots.txt文件,该文件定义了一套协议规定网络爬虫器不应该爬取或允许爬取那些区域。
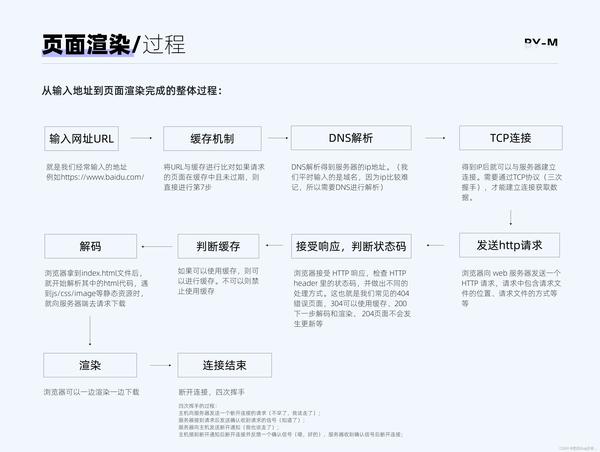
前端高频面试题分享,这题答不出来面试肯定失败。在浏览器中输入一个 URL 到页面渲染出来的过程:1. DNS 解析首先,浏览器会通过域名解析服务器(DNS)将 URL 中的域名解析成 IP 地址。该过程包括系统缓存中查找、本地 HOST 文件、本地 DNS 缓存、域名服务器递归查询等步骤,最
微信url怎么获取
短信内如何打开微信小程序某个页面?可以通过获取 URL Lik来实现,URL Lik 如图所示。通过服务端接口可以获取打开小程序任意页面的 URL Lik。服务端接口文档地址:developers.weixi.qq/miiprogram/dev/a
精准大数据获客系统:海量数据-精准获客-高效处理-价值巨大。汇智信大数据获客方式:1、指定网站/URL。数据抓取访问过指定网站/URL的用户。数据获取最近注册/登录/使用过指定APP的用户。数据抓取拨打接听过指定400电话的用户。2、指定短信验证码。数据抓取接收过特定短信通道验证码的用户。3

各位,用pytho如何快速获取(如正则表达式)下面中每一项url里面的网址信息?每一个url的信息,如第一个url信息为:/public/images/eso8807a/,,var images = [ { id: 39, title
Chrome扩展打开新页面的方法 chrome.tabs.create API,该方法只能在service worker和扩展内部的页面中执行,不能在cotet scripts里调用。若打开的网页是扩展内部的页面,需要通过chrome.rutime.getURL API获取到对应的url。
用Pytho开发一个数据抓取的爬虫ChatGpt:好的,下面是一个基本的Pytho爬虫示例,爬取一个网页中的标题和正文内容:import requestsfrom bs4 import BeautifulSoup34